- I. Introduction
- II. Two Unexpected Developments: McCarran-Ferguson and Machine Learning
- III. Advancements in Machine Learning and High-Performance Computing Obviate the Need for the Antitrust Exemption
- IV. Leaving Breathing Room for Insurers: Antitrust Analysis as Applied to Insurers in the Absence of Federal Antitrust Immunity
- V. Conclusion
I. Introduction
Several industries receive special governmental treatment: farmers receive subsidies mostly in the form of crop insurance,[1] Disney gets a steady stream of international employees through a visa it designed,[2] and—the focus of this Note—the insurance industry has the McCarran-Ferguson Act. Under the McCarran-Ferguson Act, the insurance industry enjoys immunity from the majority of federal antitrust law,[3] and this antitrust immunity has caught the attention of some commentators who have railed against it.[4] The debate has revolved around a key rationale for the exemption: insurers need to share information with competitors.[5] The rationale assumes that insurance companies need to share information to evaluate risk and price premiums accurately.[6] For instance, an insurer may calculate an insured’s risk by using historical data on the claims that that insurer has paid out, and the more data available, the better.[7] It would be difficult, so it is thought, for one insurer to collect all the requisite data on its own for calculating risk.[8]
While it may be true that more data is preferable to less, that does not mean more data is always necessary. Advancements in machine-learning (ML) techniques and computer-processing power have made it possible to reduce estimation error with fewer variables, observations, or both.[9] The implication for insurers is that ML techniques may allow an insurer to estimate the risk of its insureds accurately, even if that insurer is using data limited in length, width, or both.
The advancements in ML techniques have two implications for antitrust regulation as applied to the insurance industry. First, if insurers can accurately estimate the risk of their insureds using only their own data, then insurers do not need to share information. Thus, a key rationale for the insurance industry’s antitrust exemption is undercut. Second, if the insurance industry is subject to federal antitrust regulation, several practices engaged in by companies today might face scrutiny: sharing of historic loss data, pooling of such data, and sharing of projected trends in pricing or costs.[10] Potentially suspect activities within the insurance industry would likely be subject to a rule-of-reason analysis.[11] The question of whether insurers need to share information would bear on that analysis.
This Note aims to address the impact of advancements in ML techniques on the application of federal antitrust regulation to the insurance industry. Part II will provide background on the current system of state and federal regulation of the insurance industry, including the operation of the McCarran-Ferguson antitrust exemption and the rationales underlying it. This background is necessary to understand how federal antitrust law currently operates with respect to the insurance industry and what it would mean were that system to change. Part III will discuss advancements in ML techniques and how those advancements undercut the information-sharing rationale of the exemption—which supports the exemption’s repeal or reform. This discussion will examine what a repeal of the antitrust exemption would mean for the insurance industry. Lastly, Part IV will analyze the implications of ML advancements on a rule-of-reason analysis were such an analysis applied to the practices of insurers in the absence of McCarran-Ferguson’s exemption. This analysis will be relevant because, as discussed below, in the absence of an exemption, several practices engaged in by the insurance industry would likely be considered suspect under federal antitrust law.
II. Two Unexpected Developments: McCarran-Ferguson and Machine Learning
A. The Birth of the McCarran-Ferguson Act and the Antitrust Exemption
The insurance industry’s antitrust exemption came into existence at the end of a long saga in the Supreme Court’s Commerce Clause jurisprudence. Even before the American Revolution, states had undertaken the primary role as regulators of the business of insurance.[12] This role was imperiled in Paul v. Virginia, in which Paul, an insurance agent, challenged a Virginia statute regulating out-of-state insurance corporations.[13]
Paul’s objections to the law included: (1) Congress has the power to regulate interstate commerce; (2) Congress’s power to regulate interstate commerce is exclusive; (3) the business of insurance is interstate commerce where a corporation of one state sends its agents to another state to contract with insureds; and so, therefore, (4) Virginia’s discrimination against out-of-state insurance corporations constitutes an unconstitutional regulation of interstate commerce.[14] The Court took issue with proposition (3) and concluded:
Issuing a policy of insurance is not a transaction of commerce. . . . These contracts are not articles of commerce in any proper meaning of the word. They are not subjects of trade and barter offered in the market as something having an existence and value independent of the parties to them. They are not commodities to be shipped or forwarded from one State to another, and then put up for sale. They are like other personal contracts between parties which are completed by their signature and the transfer of the consideration. Such contracts are not inter-state transactions, though the parties may be domiciled in different States.[15]
The Court’s ruling in Paul went beyond merely upholding the Virginia statute. It had a larger implication: if the business of insurance was not—and could not be—interstate commerce, then it was outside the scope of Congress’s power under the Commerce Clause. Paul v. Virginia cemented into the place the regulatory system of the time, leaving regulation of the business of insurance to states.
The states-as-sole-regulators model would not be toppled until nearly eight decades later. In 1944, after undergoing a period of expanding the scope of Congress’s interstate commerce power,[16] the Supreme Court overruled Paul, which had categorically excluded the business of insurance from the scope of interstate commerce.[17] In South-Eastern Underwriters, the Court agreed that a contract of insurance did not “itself constitute interstate commerce,” but reasoned that, when examining the entire transaction involving procurement of insurance, “there may be a chain of events which becomes interstate commerce.”[18] Overruling Paul, the Court made clear that the scope of interstate commerce included the business of insurance.[19]
South-Eastern Underwriters was a dramatic decision not only because it destroyed a previously well-settled proposition—that the business of insurance is not a part of interstate commerce—it cast into doubt the regulatory framework to which the insurance industry had grown accustomed since the founding of the United States.[20] From this uncertainty, the insurance industry’s antitrust exemption was born.[21] Congress enacted the McCarran-Ferguson Act, which not only disclaimed Congress’s exclusive power to regulate insurance,[22] the statute granted the insurance industry an exemption from federal antitrust law.[23]
B. The Antitrust Exemption and Its Application
McCarran-Ferguson’s antitrust exemption operates in three parts: (1) The “business of insurance” is exempted from the reach of the federal antitrust laws; (2) except that these antitrust laws are applicable “to the extent that such business is not regulated by State law”; and (3) regardless of state regulation, McCarran-Ferguson does not render the Sherman Act inapplicable to “any agreement to boycott, coerce, or intimidate, or act of boycott, coercion, or intimidation.”[24] Understanding the exemption—and to what conduct or practices it applies—requires understanding what constitutes: (1) the business of insurance; (2) state regulation; and (3) boycott, coercion, or intimidation.
To determine whether a practice is a part of the “business of insurance,” the Supreme Court has identified three criteria, first announced in Group Life and Health Insurance Co. v. Royal Drug Co.[25] and later refined in Union Labor Life Insurance Co. v. Pireno: (1) “whether the practice has the effect of transferring or spreading a policyholder’s risk”; (2) “whether the practice is an integral part of the policy relationship between the insurer and the insured”; and (3) “whether the practice is limited to entities within the insurance industry.”[26] None of these factors is determinative. For example, in Pireno, the insurance company evaluated policyholders’ claims for chiropractic treatment by using a committee of chiropractors to determine “whether the treatments were necessary and whether the charges for them were reasonable.”[27] The Court determined that this practice was not a part of the business of insurance under the factors outlined above.[28] First, the practice did not involve transferring or spreading risk; the insured had already transferred her risk—the risk of needing chiropractic treatment—to the insurer.[29] Second, the practice was not an integral part of the policy relationship between the insurer and the insured; the arrangement was between the insurer and a committee of chiropractors, who themselves were clearly not involved in the business of insurance.[30] Third, this practice was not limited to entities within the insurance industry; chiropractors were outside the insurance industry and their involvement here was the kind of arrangement that “may prove contrary to the spirit as well as the letter” of McCarran-Ferguson’s antitrust exemption: “[T]hey have the potential to restrain competition in noninsurance markets.”[31] Having not received a favorable outcome on any of the Royal Drug criteria, the insurer’s practice scrutinized in Pireno was not a part of the “business of insurance.”[32]
In contrast to the foregoing analysis, the question of what constitutes state regulation has not received as much attention by federal courts.[33] However, when it has been considered, “in an antitrust case the presence of even minimal state regulation, even on an issue unrelated to the antitrust suit, is generally sufficient to preserve the immunity.”[34] In other words, if there is any state regulation of the insurance practice being scrutinized, the state-regulation requirement of McCarran-Ferguson’s antitrust exemption appears satisfied.[35] The requirement appears satisfied even if federal antitrust would be consistent with or complement existing state regulation rather than preempt it.[36]
Lastly, a practice by an insurer will not receive antitrust immunity if such practice constitutes boycott, coercion, or intimidation. The Supreme Court has defined “boycott” by distinguishing it from a closely related concept, “concerted agreement to seek particular terms in particular transactions.”[37] A “concerted agreement to seek particular terms in particular transactions” exists where parties refuse to deal with another party on a particular transaction except on the terms sought for that transaction.[38] In contrast, a boycott occurs when parties refuse to deal with another party unless that party acquiesces to their demands on unrelated transactions.[39] For example, if tenants, seeking a reduction in their rent, refused to renew their leases until such a reduction was made, that would be a concerted agreement; however, if tenants, seeking a reduction in their rent, refused to deal with their landlord at all, including refusal to sell him food or other goods, until such a reduction was made, that would be a boycott.[40] With respect to the insurance industry, the following is an example of a boycott: A group of reinsurers wants changes made to commercial, general-liability policy forms written by an association of insurers; the reinsurers refuse to offer any reinsurance to primary insurers who use the disfavored policy form, even if that primary insurer uses policy forms the reinsurers do not find objectionable.[41] Accordingly, this behavior would not receive antitrust immunity under the McCarran-Ferguson Act.[42]
C. The Exemption’s Policy Rationales
The antitrust immunity, as outlined above, provides the insurance industry with a shield, removing a cloud of doubt that might otherwise hang over certain practices, such as the use of standardized policy forms across insurers,[43] the sharing of “data regarding the identification and quantification of risks,” and the collection and dissemination of “loss and expense data.”[44]
As an example of the application of McCarran-Ferguson’s antitrust exemption, consider the practice of sharing information to accurately price premiums. First, this practice would be a part of the business of insurance: (1) the practice may not directly transfer or spread risk, but the determination of risk is a necessary part of that process; (2) determination of the frequency and severity of risk—which is what information sharing allows insurers to accomplish with precision—is an integral part of the policy relationship between the insurer and insured; and (3) the practice is only between fellow insurers and their intermediaries, e.g., rating bureaus or associations of insurers, such as the Insurance Services Office. Second, many states regulate rates,[45] and this practice indirectly influences rates, so the state-regulation requirement is met. Lastly, this practice could not conceivably be a boycott. The practice does not involve any parties demanding concessions from another. Accordingly, this practice would satisfy the requirements of McCarran-Ferguson’s antitrust exemption. Though the above analysis is not precise, one would hope its conclusion holds true. The practice is exactly the kind of thing that McCarran-Ferguson seeks to shield from federal antitrust law.[46]
Besides information sharing, the two competing rationales are standardized policy forms and the preservation of competition.[47] The information-sharing rationale is the focus of this Note because, if information sharing is not necessary, these two remaining rationales are insufficient to justify the insurance industry’s antitrust exemption. With respect to standardized policy forms, repeal of the antitrust exemption would not prevent insurers from using standardized policy forms; instead, use of these forms would simply become voluntary, as dictated by market forces rather than imposed by insurance companies or industry groups.[48] As for the preservation of competition, a rationale that maintains that smaller firms will be unable to compete without the exemption, this argument leads back to the information-sharing rationale.[49] As discussed later in this Note, smaller firms will not necessarily suffer absent an antitrust exemption if their collaborative behavior can pass a rule-of-reason analysis.[50]
Given that the information-sharing rationale is the only rationale that, if its assumption holds true, justifies the insurance industry’s antitrust exemption, it will be the focus of this Note. Under the information-sharing rationale, insurers need to cooperate by sharing claims and loss data so that premiums can be accurately priced, and this cooperation should be allowed even if it has anticompetitive effects.[51] Insurers price premiums by determining the likely losses for a given year, and to do so, insurers need information, such as losses from the prior year and factors related to the risk to be insured.[52] So that the insurer can accurately price premiums, the insurer must “rely on its ability to gather data about the risks it intends to insure . . . . This is why . . . the insurance industry is given some immunity from federal antitrust laws.”[53] That is, in order to gather data about risks, the assumption is that insurance companies need to collude: “Independent collection of national or regional loss data by each insurer would be extremely inefficient. In part for these reasons, data exchanges have been widespread in the insurance industry.”[54] Information sharing is accomplished through “insurance intermediaries.”[55] Through these intermediaries, the insurers collect and disseminate “statistical data on losses, premiums, and exposures.”[56] In addition, insurers that can accurately estimate the riskiness of individual policyholders are at a competitive advantage relative to their competitors who are unable to do so.[57]
III. Advancements in Machine Learning and High-Performance Computing Obviate the Need for the Antitrust Exemption
As previously mentioned, insurers utilize loss and claims data to predict losses and appropriately rate policyholders.[58] Often, insurers are not pricing policies through rudimentary, statistical analyses.[59] Insurers take advantage of statistical modelling to predict the frequency and severity of losses.[60] Historically, the amount of data that can be processed has been limited by the processing power and memory of existing computing resources. Today, the processing power, memory, and storage of modern computing resources have increased exponentially relative to their predecessors from decades prior.[61] These advancements in computing resources, coupled with research in data science and the growth of data collected and stored, create a perfect environment for organizations to improve their data analytics. In the context of insurance, insurers should be more able to accurately predict the frequency and severity of claims and rate the risks of their policyholders given the growth in resources and methods.
Again, the premise underpinning the information-sharing rationale behind the insurance industry’s antitrust exemption is that this practice “permits insurance companies to evaluate risk and price insurance accurately.”[62] The idea is that if an insurer were to collect on its own a volume of data sufficient to estimate risk with the desired level of precision, collecting this data would either (1) be prohibitively expensive or (2) economically inefficient because insurers duplicate each other’s efforts. Insurers already collect information from their insureds, so this rationale relies on the assumption that the collected data of a single insurer—especially a small insurer in a property-and-casualty line of insurance—is insufficient to accurately predict risk and price policies appropriately.[63] This rationale also relies on the assumption that these collaborative practices would be prohibited by federal antitrust law absent an exemption.[64]
A. Something Old, Something New: Comparing a Traditional Technique Against a Machine-Learning Method
Advancements in machine learning challenge the assumption that more data leads to greater prediction accuracy. Specifically, new algorithms—easily utilized due to improvements in computer processing power, memory, and storage—can achieve high levels of precision even if data volume is decreased. One way to determine whether an algorithm actually performs better than another is to see how quickly that algorithm “learns” the problem that it is given.[65]
Consider a rudimentary problem: predicting whether a given individual makes more than $50,000 using employment-related and demographic information. In this example, I will compare the performance of two algorithms: Random Forests and logistic regression. Logistic regression was developed in the 1950s whereas Random Forests appeared in the '90s.[66] Accordingly, logistic regression represents the “old.” Meanwhile, Random Forests represents the “new.” A logistic regression model is used for binary outcomes and can be used to predict the probability of an outcome occurring.[67] Random Forests is a method that “grows” many decision trees, randomly sampling from the records contained in the training set and also randomly sampling the variables. The result is an ensemble of the trees grown. This Random Forests model can then be used to predict the outcome variable given information about the input variables.[68]
For this example, I use a subset of data from the 1994 U.S. Census database.[69] The dataset being utilized contains 48,842 observations, which are split between a training set and testing set.[70] There are also fourteen employment-related and demographic variables.[71] Models will be built using the training data and then tested using the test data. I utilize progressive sampling, in which the size of the training set starts small and increases progressively to some specified point.[72] In this example, the models are trained on training sets that begin at .05% (n = 16) of the total training-set size. The training-set size increases in increments of .05 percentage points until the training-set size reaches 4% (n = 1,302) of the total training-set size. Each trained model is tested on the full test set (n = 16,281). This progressive sampling process produces a learning curve that shows how quickly each algorithm “learns” the problem.[73] In total, due to this progressive sampling method, eighty logistic regression models were fitted (one model for each training-set size). As for the Random Forests method, because Random Forests randomly samples variables and observations, its performance can vary; accordingly, ten Random Forests models were fitted for each training-set size for a total of 800 fitted models.
For the logistic regression model, all independent variables were used as predictors. Additionally, a probability above .5 is treated as a prediction that an individual has an annual income above $50,000. For the Random Forests model, 1,000 decision trees were “grown” with variables being randomly selected each time and the final decision tree being an average of the 1,000 trees. Both models were trained on the training data and then tested on the test data.[74] These models were fitted without much tuning–specifically, input, or predictor, variables were not carefully chosen and assumptions underlying the theoretical models were not tested.[75]
This problem is roughly comparable to an insurer predicting the volume of claims that a policyholder might generate.[76] Though claims or loss data—the kind an insurer would use for its analysis—differ in structure from the data presented here, there are similarities. First, insurers take advantage of a variety of demographic information in their analyses.[77] Second, depending on the analysis being performed, such as predicting the frequency of auto claims for a pool of insured drivers, the data on which the insurer bases its analysis is likely imbalanced; the data contains more instances of insureds who report no accidents versus those who do.[78] The data used here is also imbalanced: within the training set, only 24.1% of individuals have an annual income above $50,000.[79]
B. Newer Machine-Learning Methods Outperform Traditional Techniques
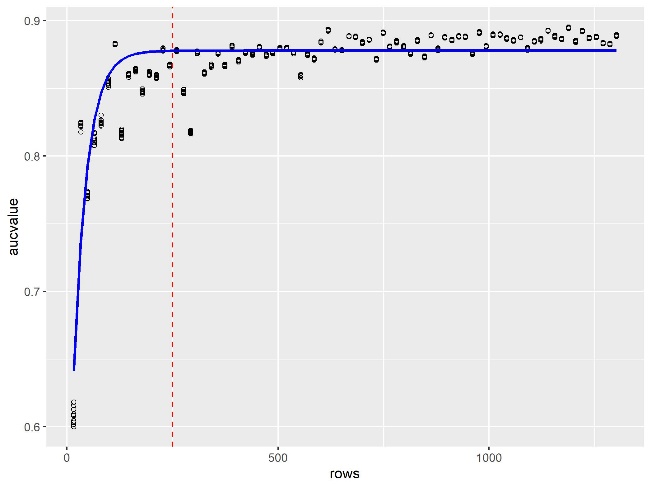
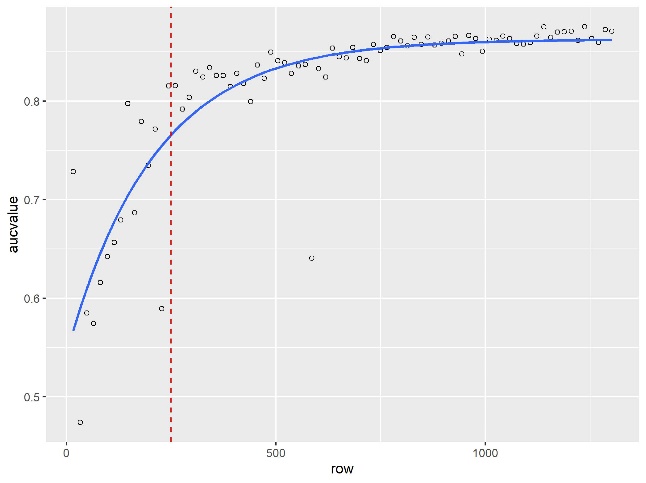
As the results in Figure 1 show, the Random Forests algorithm—the newer machine learning method—“learned” faster than logistic regression, meaning that the performance of the Random Forests model began to plateau before the performance of the logistic regression model.


On the top is the learning curve of the Random Forests models. On the bottom is the learning curve of the logistic regression models. The blue line is an asymptotic regression model fitted to each learning curve, where model performance is a function of: (1) the size of the training set; (2) the horizontal asymptote; (3) the model’s performance when the training-set size is set to zero; and (4) the natural logarithmic constant of the rate at which the model “learns.” The dashed, red line is set to x = 250 to show each model’s relative performance at a training-set size of 250 observations. The x-axis is the number of observations included in the training set to fit the model. The y-axis is the area under the Receiver Operating Characteristics curve (AUC) value of the fitted model when used to predict the testing set.
For this example, the chosen performance metric was the AUC. The AUC ranges from zero to one and reflects the tradeoff between the true-positive and false-positive rates.[80] If AUC equals zero, that means the model gets nothing right. If AUC equals one, the model predicts the outcome perfectly (e.g., it correctly predicts that someone makes more than $50,000 every time, and it is never wrong when it predicts that someone makes less than or equal to $50,000).[81] There are a variety of performance measures that could have been chosen,[82] but AUC has advantages over more commonly known metrics, such as accuracy.[83]
Over time, both models achieve approximately the same level of performance. The Random Forests algorithm has a predicted peak AUC of 0.878, and the logistic-regression algorithm has a predicted peak of 0.887. However, as seen in Figure 1, the Random-Forests algorithm approaches the peak much more quickly—it “learns” the classification problem faster.
These results are consistent with the work of others who have analyzed model performance over varying sample sizes.[84] Researchers Sordo and Zeng compared the ability of three learning algorithms—Naïve Bayes, Decision Trees, and Support Vector Machines (SVM)—to classify data while varying the size of the training sets from around 2% to 100% of the total number of cases available, which was 8,500.[85] While initial increases in sample size led to substantial improvements in the classification accuracy of all three models, for two of the models—Decision Trees and SVM—most of the gains were achieved at the 2,000-observation mark, and little improvement occurred after the 4,000-observation mark.[86]
C. Algorithms that “Learn” Faster Mean that the Information-Sharing Rationale Is No Longer Justified
Analogizing to the insurer context, the above results mean that information sharing may not be so vital. After all, the assumption underlying the information-sharing rationale is that more data leads to exponentially better results.[87] The example problem presented above—along with the research of others who have studied model performance—lends credibility to the argument that there is an “efficiency threshold”[88] that, once crossed, does not lead to exponentially better results in accuracy or other measures of performance.
These results undermine the information-sharing rationale. Understandably, in 1945 when the McCarran-Ferguson Act became law,[89] advancements in machine learning and processing power did not exist. Insurers on their own likely could not carry out predictive analyses with the level of precision necessary to stay in business. However, in light of these results, the supposed need for more data seems less apparent. If even small insurers can achieve comparable levels of prediction performance relative to their competitors using only their own data,[90] then information sharing is not a necessary practice in the insurance industry. With the information sharing rationale undercut, the insurance industry’s exemption from federal antitrust law has little justification.[91] To repeat, the idea behind the antitrust exemption is (1) the insurance industry engages in certain practices, such as information sharing, that would be suspect under antitrust law, and (2) these practices are necessary to the business of insurance, and so (3) these practices should be given immunity.[92] This idea works like a per se rule of illegality in reverse. In antitrust analysis, when conduct is scrutinized, if the per se rule is applied, the challenged practice is by nature considered illegal, and no proof of anticompetitive effects is required.[93] With this antitrust exemption—or exemptions in general—the thinking goes the other way: the challenged practices, at first glance, might appear anticompetitive, but in the majority of cases, these practices will turn out to be procompetitive.[94]
Yet, with the necessity of information sharing challenged, it is no longer clear that insurers must engage in this practice to compete effectively. Regardless of whether information sharing leads to procompetitive or anticompetitive effects—which would be the focus of an antitrust analysis—if a practice is not a necessity, there seems to be little ground for giving that practice blanket immunity from federal antitrust law.
IV. Leaving Breathing Room for Insurers: Antitrust Analysis as Applied to Insurers in the Absence of Federal Antitrust Immunity
Given that this Note advocates for the repeal of McCarran-Ferguson’s antitrust exemption for the insurance industry, it begs the question: What does a world without this exemption look like? In a post-McCarran-Ferguson world, there may be circumstances in which collaborative conduct among insurers should withstand an antitrust inquiry. Without an exemption, the insurance industry would face the same scrutiny under federal antitrust laws as any other industry would.[95] Were collaborative conduct by insurers to come under scrutiny, it would most likely be under § 1 of the Sherman Act, which states, “Every contract, combination in the form of trust or otherwise, or conspiracy, in restraint of trade or commerce among the several States, or with foreign nations, is declared to be illegal.”[96] In a § 1 analysis, some practices are “so plainly anticompetitive that no elaborate study of the industry is needed to establish their illegality.”[97] Such practices are considered per se illegal. However, courts are reluctant to label a practice as per se illegal.[98] If there is no per se rule to apply, courts will apply the rule of reason, under which “the factfinder weighs all of the circumstances of a case in deciding whether a restrictive practice should be prohibited as imposing an unreasonable restraint on competition.”[99] Several commentators believe that were McCarran-Ferguson’s antitrust exemption repealed, collaborative information-sharing would be subject to a rule-of-reason analysis and not a per se rule.[100] Importantly, § 1 only applies to “concerted action,” and so a plaintiff would need to establish that the requisite concerted action is present before even proceeding to a rule-of-reason analysis.[101] This Note assumes that collaboration between insurers—indirectly through intermediaries—constitutes “concerted action.”[102]
Were the insurance industry stripped of its federal antitrust immunity, courts faced with potential federal antitrust violations should bear in the mind the advancements in machine learning and computing resources discussed in this Note.[103] The discussion of the necessity of information sharing is not only relevant to the repeal of McCarran-Ferguson’s antitrust exemption but to the legality of information sharing under an antitrust analysis.
Under a rule-of-reason analysis—regardless of the defendant’s industry—courts typically employ a four-step, burden-shifting approach characterized by Professor Carrier:
First, the plaintiff must show a significant anticompetitive effect, typically in the form of a price increase, output reduction, or market power. . . . Second, the burden shifts to the defendant to demonstrate a legitimate procompetitive justification. . . . Third, if the defendant successfully makes this showing, the burden shifts back to the plaintiff to demonstrate that the restraint is not reasonably necessary to achieve the restraint’s objectives or that the defendant’s objectives could be achieved by less restrictive means. . . . Fourth, the court balances the restraint’s anticompetitive and procompetitive effects, which occurred in 4 percent of the cases.[104]
In the case of an insurer, the relevance of machine learning comes into play after the first step, in which the plaintiff has shown that information sharing has a significant anticompetitive effect.[105] Under steps two and three, an insurer would want to show that its reliance on information from other insurers—obtained through intermediaries—is a “legitimate procompetitive justification,” while the plaintiff would want to show that the information sharing is not “reasonably necessary.” The question then becomes: Assuming that the accurate estimation of risk is a legitimate procompetitive justification, is information sharing reasonably necessary?
This analysis should differ depending on the relative size and seniority of the insurer: (1) new entrant; (2) established small insurer;[106] or (3) established large insurer. The third category can be disposed of easily: There is no apparent need for an established, large insurer to utilize competitors’ information, because a large insurer should already have sufficient data to accurately predict risk and price premiums. As for the first category, information sharing to facilitate entry into insurance markets should likely not be prohibited because of its procompetitive effects.[107]
The middle category likely presents the most trouble. While the goal of this Note is not to fully anticipate or simulate a rule-of-reason analysis as applied to insurers engaged in information sharing, any rule-of-reason analysis should consider the available statistical and computing resources that insurers—and all companies—have today. In a rule-of-reason analysis, a highly relevant question would be: Considering the information that the scrutinized insurer could obtain through only its own efforts, does it have sufficient information to predict costs and risks with an accuracy comparable to that of a large, established insurer? Both plaintiffs and defendants could conduct performance analyses much like that in the Sordo and Zeng study previously mentioned, which compared the efficacy of three classification models.[108]
Before conducting a performance analysis, two questions must be answered: (1) what is the task to be performed; and (2) what is the measure of performance to be used? In the Sordo and Zeng study, the models were tasked with classifying patients’ smoking statuses based on discharge reports.[109] Accuracy was the measure of performance. In an antitrust analysis applied to information sharing among insurers, the task to be performed should be straightforward: claim frequency, claim severity, risk rating. Determining the measure of performance will depend on the goal of the analysis. Though Sordo and Zeng chose accuracy as their performance indicator, this is not always the best measure of performance.[110] Furthermore, accuracy is only a potential measure of performance when the outcome is a factor variable.[111] When it comes to actual analysis of the data, a statistical method for classification or regression must be chosen and the appropriate model specified. For example, in the income example in Part III, logistic regression was one of the two chosen methods with the specified model being the log of the odds of a record classified as “income above $50,000” as a function of thirteen independent variables.[112] In an antitrust enforcement action or private action,[113] the insurer, under this framework, will be motivated to show that, given the insurer’s own data, no statistical method can predict or classify the target variable with the degree of performance[114] necessary for the insurer to compete effectively. The plaintiff will be motivated to show that, given the insurer’s own data, there is a method available that can provide the degree of performance necessary to compete effectively.
At this stage, the performance analyses and the learning curves they produce must be evaluated.[115] In the income example presented in Part III of this Note, there was enough information available to sufficiently predict whether someone made more than $50,000 or less than or equal to that amount.[116] Accordingly, I could produce a complete learning curve. That is, I had enough observations to demonstrate that any marginal increase in the size of the training set did not improve the performance—measured by AUC—of the models.[117] The more puzzling scenario is: Insurer has a dataset of X rows and Y columns that it uses to estimate Z. Insurer is unsure whether the size of this dataset is sufficient to accurately estimate Z. In this scenario, let’s assume that Insurer’s volume of data is insufficient—it will not produce a sufficiently accurate estimate of the desired metric, such as claim severity or claim frequency. Assuming that the volume of data is insufficient, can Insurer figure that out by producing a learning curve? That is, will that learning curve be useful given that the size of the dataset is insufficient? Scholarship in this area answers, “Yes.”[118] Using the data it has available, an insurer can still forecast a learning curve to discern whether it has sufficient data to surpass the efficiency threshold, the point at which improvements in model performance become trivial or marginal.[119] If an insurer truly does not have enough data to complete the relevant insurance-related task, the forecasted learning curve will make this apparent—taking into consideration an error in the accuracy of the predicted learning curve.
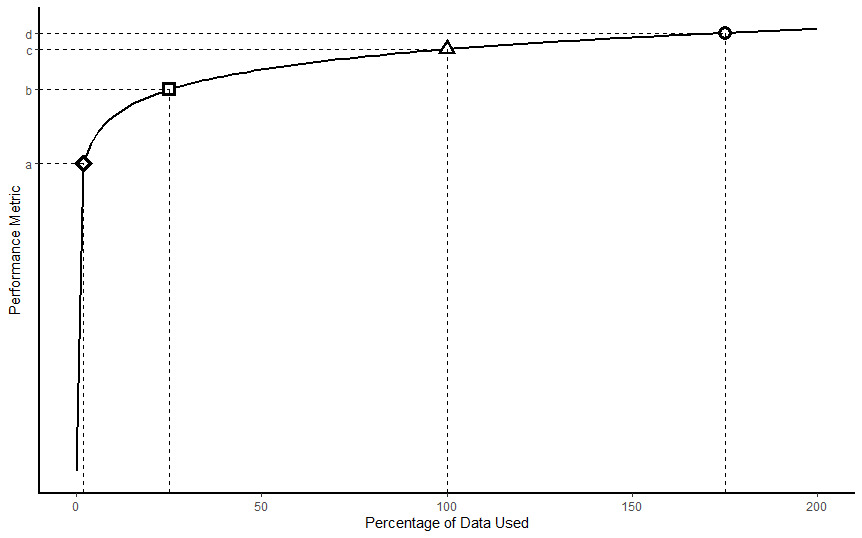
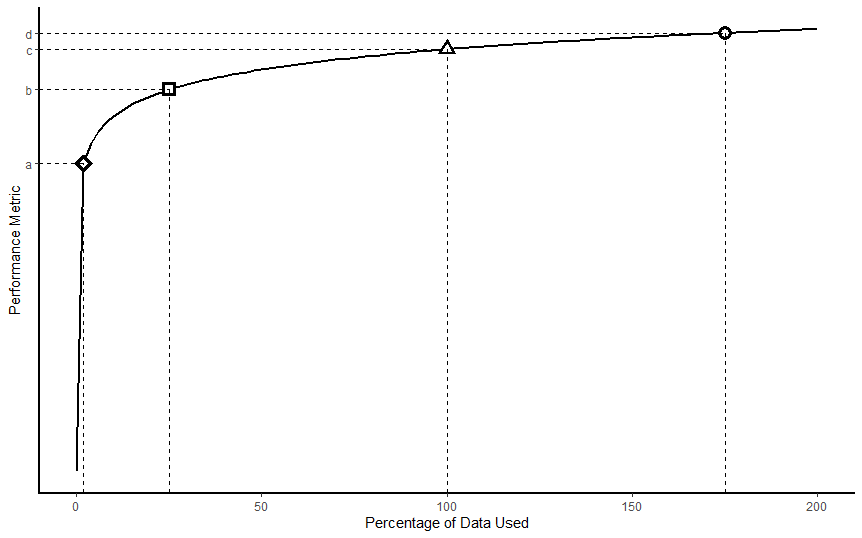
Now, consider a situation where the relationship between the percentage of data used and the chosen performance measure (e.g., accuracy) is represented in the graph below. This is similar to the relationship observed between accuracy and percentage of data used in the Sordo and Zeng study.[120] A performance analysis would produce a learning curve like this. In this hypothetical, the scrutinized insurer achieves a level of performance c when utilizing 100% of its own data—and only its own data. When using only 2% of its data, the insurer achieves a level of performance a. Most of the gains in performance are achieved before level c is reached. Though the graph cannot definitively answer the question whether information sharing is necessary for this insurer, it suggests that the insurer may have enough information to complete the relevant, insurance-related task.[121] This finding would weigh against allowing an insurer to engage in collaborative information sharing with other insurers because such a practice does not lead to much gain in performance. In other words, information sharing is not reasonably necessary to achieve a procompetitive effect: accurately estimating risk. Application of the foregoing analysis assumes that such additional information may be used for anticompetitive collusion[122] and that information sharing actually has an anticompetitive effect.[123]
Given that insurers can produce learning curves to demonstrate whether they can achieve sufficient performance in completing relevant insurance-related tasks, there is no reason why insurers should fear the repeal of their federal antitrust immunity. Without this immunity, should an insurer face an antitrust action,[124] it can still show that its collaborative conduct is necessary or procompetitive. Accordingly, we should not let insurers hide behind blanket immunity, and insurers need not fear that they have no recourse to demonstrate the necessity of collaborative conduct, should such conduct be necessary at all.
V. Conclusion
Since the dawn of federal antitrust law, the insurance industry has been virtually immune from federal antitrust scrutiny. For most of the history of the United States, the industry was thought beyond federal regulation. When that view shifted in South-Eastern Underwriters, the McCarran-Ferguson Act became the industry’s new antitrust shield. Today, a rationale given for the exemption is that insurers engage in collaborative practices, especially forms of information sharing, that are necessary for insurers to compete effectively.
However, advancements in machine learning and computing resources have taken data analytics to a new level. New statistical methods, which had not been developed at the time of McCarran-Ferguson or were too computationally expensive to implement, are now available and widely used. These methods have the potential to obviate the need for information sharing, and if information sharing is not necessary, then a key rationale for the insurance industry’s federal antitrust exemption is swept away.
Furthermore, absent an exemption, were insurers to become targets of antitrust actions due to collaborative information-sharing, these same considerations—advancements in machine learning and computing resources—should be relevant to the question of whether the scrutinized practice is an “unreasonable restraint on trade” under a rule-of-reason analysis. Plaintiffs and defendants in would-be antitrust suits should consider performance analyses of an insurer’s models and data to guide them in determining whether information sharing is reasonably necessary or procompetitive. Where information sharing is shown to produce an anticompetitive effect, if a defendant cannot put forward a legitimate procompetitive justification for information sharing or rebut plaintiff’s evidence that such a practice is not reasonably necessary, then an insurer should not receive a special exemption. It should be treated like every other market player.
Mason Malone
See Andrea Freeman, The 2014 Farm Bill: Farm Subsidies and Food Oppression, 38 Seattle U. L. Rev. 1271, 1292–93 (2015).
See Kit Johnson, The Wonderful World of Disney Visas, 63 Fla. L. Rev. 915, 922–25 (2011). The Immigration Act of 1990 created a new visa—the Q visa—which “was quickly dubbed the ‘Disney visa’” because of Walt Disney World’s involvement in securing the creation of this new visa. The new visa applied to “‘international cultural exchange program[s]’ in which the international worker would, as part of his employment, share ‘the history, culture, and traditions of the country of the alien’s nationality.’” Id. at 923–25 (quoting 8 U.S.C. § 1101(a)(15)(Q)(i)).
See 15 U.S.C. §§ 1011, 1012(b), 1013(b).
See, e.g., Christine A. Varney, Antitrust Immunities, 89 Or. L. Rev. 775, 781 (2011) (“One example of an exemption that I believe it is time to retire is the exemption for ‘the business of insurance’ contained in the McCarran-Ferguson Act.”); Erin K. Powrie, Note, “Too Big to Fail” Is Too Big: Why the McCarran-Ferguson Exemption to Federal Antitrust Enforcement of Insurance Is Past Its Prime, 63 Rutgers L. Rev. 359, 381–84 (2010) (discussing attempts to repeal or reform McCarran-Ferguson’s antitrust exemption); Antitrust Modernization Comm’n, Report and Recommendations 350 (2007) (“Statutory immunities from the antitrust laws should be disfavored.”); cf. Paul L. Joskow & Linda McLaughlin, McCarran-Ferguson Act Reform: More Competition or More Regulation?, 4 J. Risk & Uncertainty 373, 393 (1991) (“[S]imple repeal of the McCarran-Ferguson Act’s antitrust exemption, without more, is likely to do more harm than good.”).
See Jonathan R. Macey & Geoffrey P. Miller, The McCarran-Ferguson Act of 1945: Reconceiving the Federal Role in Insurance Regulation, 68 N.Y.U L. Rev. 13, 47–53 (1993); cf. Antitrust Modernization Comm’n, supra note 4, at 351 (arguing that absent an antitrust exemption for the insurance industry “such data sharing would be assessed by antitrust enforcers and the courts under a rule of reason analysis that would fully consider the potential procompetitive effects of such conduct and condemn it only if, on balance, it was anticompetitive”).
Macey & Miller, supra note 5, at 47; see also Terry J. Houlihan, Applying the Antitrust Laws to the Insurance Industry, Antitrust, Fall/Winter 1989, at 20, 20.
See Ivan Maddox, The Caveat to Historical Claims Data, Intermap: Risks Hazard Blog (Feb. 2, 2015, 12:54 PM), https://www.intermap.com/risks-of-hazard-blog/2015/02/danger-of-relying-on-historical-claims-data [https://perma.cc/G63G-LW5K].
Houlihan, supra note 6, at 20.
See Justin Sirignano & Kay Giesecke, Risk Analysis for Large Pools of Loans, 65 Mgmt. Sci. 107, 116, 119–20 (2019) (testing new approximation models to estimate loan risk and finding “that the approximation has very high accuracy even for small pools in the hundreds of mortgages”); Rosa L. Figueroa et al., Predicting Sample Size Required for Classification Performance, 12 BMC Med. Informatics & Decision Making, Feb. 15, 2012, at 1, 7 (noting that, in the context tested, a sample of “moderate size” [n = 100~200] could still produce results with an “acceptable” margin of error).
See Anthony J. Alt, Congress’ Self-Inflicted Sisyphean Task: The Insurance Industry’s Federal Antitrust Exemption and the Insurance Industry Competition Acts of 2007 and 2009, 16 Conn. Ins. L.J. 399, 427–29 (2010).
Id. at 402.
See Christopher C. French, Dual Regulation of Insurance, 64 Vill. L. Rev. 25, 37 (2019).
Paul v. Virginia, 75 U.S. 168, 177 (1868). The Virginia statute and the Court’s discussion refers to “foreign” corporations; however, “foreign” refers to entities not incorporated in the state, i.e., in this case, Virginia. Id. at 177, 181–82.
Id. at 171–74 (explicating Paul’s argument).
Id. at 183.
For a discussion of the Supreme Court’s expansion of the interstate commerce power, particularly during the New Deal era, see Richard A. Epstein, The Proper Scope of the Commerce Power, 73 Va. L. Rev. 1387, 1443–54 (1987).
See United States v. Se. Underwriters Ass’n, 322 U.S. 533, 552–53 (1944).
Id. at 546–47. As an aside, the Court in South-Eastern Underwriters rationalized its reversal of Paul v. Virginia by noting that, in Paul, the Court considered whether to strike down a state law regulating insurance, whereas in the instant case, the petitioner had asked the Court to strike down an Act of Congress. Id. at 544–45. This rationalization comports with the Court’s expansion of its Commerce Clause jurisprudence during the New Deal era. See Epstein, supra note 16.
Se. Underwriters Ass’n, 322 U.S. at 553 (“No commercial enterprise of any kind which conducts its activities across state lines has been held to be wholly beyond the regulatory power of Congress under the Commerce Clause. We cannot make an exception of the business of insurance.”).
See French, supra note 12, at 40 (“[B]eginning in 1944, the insurance industry became subject to federal regulation and federal antitrust laws. This change in the regulatory regime was of great concern to both insurers and the states.”).
Id. at 40–41.
See Macey & Miller, supra note 5, at 20 (noting that Congress has provided for “mixed regulatory systems in which the states play a prominent role,” but that Congress rarely takes the step to “expressly assign the states exclusive regulatory jurisdiction over an area of commerce or so clearly disavow the value of federal regulation” as it did in the McCarran-Ferguson Act).
The antitrust exemption derives from two provisions of the McCarran-Ferguson Act codified as 15 U.S.C. §§ 1012(b) and 1013(b). Section 1012(b) provides that after a transitional period has elapsed, the Sherman Act, the Clayton Act, and the Federal Trade Commission Act will apply to the business of insurance only if such business is not regulated by state law. Section 1013(b) carves out an exception to the exemption: the Sherman Act will apply to “any agreement to boycott, coerce, or intimidate, or act of boycott, coercion, or intimidation.”
15 U.S.C. §§ 1012(b), 1013(b).
Grp. Life & Health Ins. Co. v. Royal Drug Co., 440 U.S. 205, 211, 215–16, 224 (1979).
Union Lab. Life Ins. Co. v. Pireno, 458 U.S. 119, 129 (1982).
Id. at 123.
Id. at 129.
Id. at 130. At this point, it should be noted that the Court’s decision in Pireno appears to narrow the scope of the exemption in the McCarran-Ferguson Act. The plain text of the exemption might suggest a blanket antitrust exemption for any conduct of an insurer, save for acts of boycott, coercion, or intimidation. See 15 U.S.C. §§ 1012(b), 1013(b). Indeed, even under the “business of insurance” factors, it is hardly a stretch to argue that evaluating whether a claim is covered necessarily involves the transfer or spread of risk because if an insurer pays a claim for which it is not liable, it has transferred an uninsurable risk to itself. As noted, the Court did not accept this argument. The Court construes antitrust exemptions narrowly. Pireno, 458 U.S. at 126, 129–30. The Court’s narrowing of McCarran-Ferguson’s antitrust exemption has not gone unnoticed by other commentators. See, e.g., Robert H. Jerry II, The Antitrust Implications of Collaborative Standard Setting by Insurers Regarding the Use of Genetic Information in Life Insurance Underwriting, 9 Conn. Ins. L.J. 397, 421 (2003); Arthur J. Marinelli, The Role of Antitrust Law in the Health Care Field, 1984 Det. Coll. L. Rev. 687, 696 (1984); John Shepard Wiley Jr., A Capture Theory of Antitrust Federalism, 99 Harv. L. Rev. 713, 713 n.1 (1986) (referencing the Royal Drug decision, which is Pireno’s predecessor case).
Pireno, 458 U.S. at 131. Here, the Court suggests that where agreements are not between the insurer and the insured, the antitrust exemption likely will not apply. Again, this appears to be a severe narrowing of the broad language of the exemption.
Id. at 132–34.
Id. at 134.
Phillip E. Areeda & Herbert Hovenkamp, 1 Antitrust Law ¶ 219c (2d. ed. 2000).
Id.
Any regulation is likely not hyperbole. For example, in Federal Trade Commission v. National Casualty Co., the Supreme Court did not inquire into the application of state regulation to the insurance industry so long as the regulation was not “mere pretense.” 357 U.S. 560, 564 (1958) (per curiam). However, the regulation must cover the practice being scrutinized; it is not sufficient that a state merely has regulations that apply to insurers. See Macey & Miller, supra note 5, at 29.
See Areeda & Hovenkamp, supra note 33. Section 2b of the McCarran-Ferguson Act, codified as 15 U.S.C. § 1012(b), reads:
No Act of Congress shall be construed to invalidate, impair, or supersede any law enacted by any State for the purpose of regulating the business of insurance . . . Provided, That . . . [federal antitrust laws] shall be applicable to the business of insurance to the extent that such business is not regulated by State law.
A reasonable interpretation of the text of the statute is that federal antitrust law is not preempted by state law where federal law does not “invalidate, impair, or supersede” state regulation. That interpretation has not taken hold in the courts. See Areeda & Hovenkamp, supra note 33.
Hartford Fire Ins. Co. v. California, 509 U.S. 764, 801–02 (1993) (Scalia, J., delivering the opinion of the Court with respect to Part I).
Id.
Id. at 802–03. The Court notes that for the purposes of the Sherman Act, it is irrelevant whether an act is a boycott or concerted agreement—both are unlawful. Id. at 803. The distinction is only relevant for purposes of the antitrust immunity in the McCarran-Ferguson Act. See 15 U.S.C. § 1013(b). Additionally, the Court rejected the insurer’s argument that a “boycott” meant “an absolute refusal to deal on any terms,” i.e., there is nothing the other party can do to bring me to the bargaining table. Hartford Fire Ins. Co., 509 U.S. at 801.
Hartford Fire Ins. Co., 509 U.S. at 802–03.
See id. at 810. These are the facts of Hartford Fire. Importantly, this is the alleged behavior of the reinsurers. See id. Still, the Court held that these allegations, if proven, would amount to a boycott. Id.
The narrow definition of “boycott” adopted by the Court in Hartford Fire calls into question whether “coercion” or “intimidation” have any independent meaning. See Jerry, supra note 29, at 432–33. Under Hartford Fire, a “boycott” requires parties to seek concessions from another party. See 509 U.S. at 803 (noting that a boycott exists where “unrelated transactions are used as leverage to achieve the terms desired”). As Professor Jerry notes: “[I]f the insurers are entering into [an] agreement without any effort to extract concessions on other collateral matters, it is difficult to imagine how such conduct would fall within the ambit of ‘coercion’ or ‘intimidation[.]’” Jerry, supra note 29, at 433. In other words, it appears that if an insurer’s conduct satisfies the business-of-insurance and state-regulation requirements of McCarran-Ferguson’s antitrust immunity, it will only lose that immunity if the conduct constitutes a “boycott” under Hartford Fire, because “boycott” as used in that decision appears to swallow up any independent meaning of “coercion” and “intimidation.”
Macey & Miller, supra note 5, at 53. For example, the insurers in Hartford Fire used standardized policy forms provided through an association of insurers, the Insurer Services Office. 509 U.S. at 772.
Jerry, supra note 29, at 400.
See Macey & Miller, supra note 5, at 28–29.
See id. at 47.
See id. at 53–57.
See id. at 53–54.
See id. at 54–57.
See infra Part IV.
See Macey & Miller, supra note 5, at 47–48.
Pietro Parodi, Pricing in General Insurance 98 (2015).
Ronen Avraham, The Economics of Insurance Law—A Primer, 19 Conn. Ins. L.J. 29, 39 (2012).
Houlihan, supra note 6.
Daniel Schwarcz, Ending Public Utility Style Rate Regulation in Insurance, 35 Yale J. on Regul. 941, 968 (2018).
Id.
Parodi, supra note 52, at 450–54, demonstrates that a competitor that can accurately price policyholders based on their risk factors will capture a larger share of the market relative to a competitor that operates under a one-price-fits-all model. While this example presents two extremes—knowing some risk factors versus knowing none—the principle still holds true: the insurer that can more accurately estimate a policyholder’s level of risk will have a competitive advantage. See id.
Supra Section II.C.
For example, an insurer could price a general commercial liability policy for a policyholder simply by averaging the policyholder’s past losses, but this has the potential of producing a price that does not fully reflect the risk the insurer bears because the insurer is not accounting for “incurred-but-not-reported” claims, “claims inflation,” changes in exposure, or the policyholder’s risk profile. See Parodi, supra note 52, at 3–11.
See id. at 158–60.
See Raouf Boutaba et al., A Comprehensive Survey on Machine Learning for Networking: Evolution, Applications and Research Opportunities, 9 J. Internet Servs. & Applications, June 21, 2018, at 1, 88; Wei Pan et al., The New Hardware Development Trend and the Challenges in Data Management and Analysis, 3 Data Sci. & Eng’g 263, 264 (2018) (discussing recent advancements in storage and processor technologies); Junfei Qiu et al., A Survey of Machine Learning for Big Data Processing, EURASIP J. on Advances Signal Processing, May 28, 2016, at 1, 4–5 (noting that, even today, data volume creates challenges for data analytics).
Macey & Miller, supra note 5, at 47.
See Avraham, supra note 53; Houlihan, supra note 6; Schwarcz, supra note 55.
This assumption is questionable and is rebutted infra Part IV.
See, e.g., Figueroa et al., supra note 9, at 2–3 (discussing progressive sampling in which the training data size is increased “until a termination criteria is met,” such as a plateauing of the chosen performance metric); Margarita Sordo & Qing Zeng, On Sample Size and Classification Accuracy, in Biological & Medical Data Analysis 193, 197–98 (José Luis Oliveira et al. eds., 2005) (discussing the improvement in the predictive power of three different algorithms as the training size is increased).
Boutaba et al., supra note 61, at 11, 14.
For a brief explanation of logistic regression accompanied by practical examples, see Peter Bruce & Andrew Bruce, Practical Statistics for Data Scientists 184–93 (1st ed. 2017).
See id. at 228–33.
Ronny Kohavi & Barry Becker, Adult Data Set, UCI Mach. Learning Repository (May 1, 1996), https://archive.ics.uci.edu/ml/datasets/adult [https://perma.cc/CXG3-4PCZ].
Of the 48,842 observations, 32,561 observations are in the training set and 16,281 observations are in the testing set. Id.
The included variables are: (1) Age; (2) Work classification (e.g., self-employed, private, or federal government employee); (3) Education, as a categorical variable (e.g., Bachelor’s or some college); (4) Education, as a continuous variable (i.e., the number of years of schooling); (5) Marital status; (6) Occupation (fifteen categories; e.g., tech support or sales); (7) Relationship to head of household (e.g., wife or unmarried); (8) Race (five categories); (9) Sex; (10) Capital gains; (11) Capital loss; (12) Hours worked per week; (13) Native country; and (14) Income, expressed as categorical variable of two classes: (a) earns $50,000 or less or (b) earns more than $50,000. Id.
See Figueroa et al., supra note 9, at 2–3.
For a discussion of learning curves in the context of classification models, see id. at 2.
The models “learned” from the training set. In the case of logistic regression, this means that the model is fitted using maximum likelihood estimation, which produces parameter estimates that maximize the probability of observing the given set of data. See Bruce & Bruce, supra note 67, at 190. For a simple example, consider a set of ten coin-flips with four “heads” and six “tails.” The probability of heads that makes observing this set of flips most likely is p = 0.4. In the case of Random Forests, the model repeatedly samples from the available variables and selects values of those variables that best divide the data into the target classes (e.g., ≤$50K or >$50K). See id. at 230–31.
In a practical situation, models would be tuned to improve their performance. For logistic regression, a practitioner should carefully select the independent variables that will be used to predict the outcome as well as set the desired probability cutoff. For a Random Forests model, a practitioner should tune the model’s hyperparameters, such as the number of trees that are grown or the number of independent variables used in each tree. See id. at 236–37.
See, e.g., Peng Shi et al., Dependent Frequency–Severity Modeling of Insurance Claims, 64 Ins.: Mathematics & Econ. 417, 422–24 (2015) (estimating automobile accident frequency based on observed driver characteristics, such as age).
For example, when an insurer assigns a rating to a potential or current policyholder, a value which attempts to estimate the riskiness of that individual with respect to the risk being insured, it is common for some insurers to use twenty or more variables in their analysis, depending on the line of insurance. See Parodi, supra 52, at 449, 454.
For example, in 2018, claim frequency for auto collisions was 6.13 per 100 earned car years, where one car year is equal to 365 days of insured coverage for one vehicle. Facts + Statistics: Auto Insurance, Ins. Info. Inst., https://www.iii.org/fact-statistic/facts-statistics-auto-insurance (last visited Dec. 23, 2020) [https://perma.cc/VR6M-YM39].
Kohavi & Becker, supra note 69.
Naeem Seliya et al., A Study on the Relationships of Classifier Performance Metrics, in ICTAI 2009: 21st IEEE International Conference on Tools with Artificial Intelligence 61 (2009).
Sarang Narkhede, Understanding AUC - ROC Curve, Towards Data Sci. (June 26, 2018), https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5 [https://perma.cc/8EMY-JB44].
See Seliya et al., supra note 80, at 59–60.
In this example, a model that unconditionally classified every observation in the test data as “earns less or equal to $50,000” would have an accuracy rate of 76.4% because that is the share of observations in the test set that earn less than or equal to $50,000. The logistic model had an accuracy rate of 85.2%, while the Random Forests model had an accuracy rate of 86.2%. Accuracy, especially within imbalanced data, is not the best measure of performance because, as mentioned, even a model that blindly assigned every observation to one class would be right more than three out of four times. In most practical situations involving imbalanced data, a practitioner will want to improve the model’s ability to correctly classify the minority class, even if this improvement comes at the cost of lower accuracy. See Guo Haixiang et al., Learning from Class-Imbalanced Data: Review of Methods and Applications, 73 Expert Sys. with Applications 220, 227 (2017) (“Accuracy is the most commonly used evaluation metric for classification. However, under imbalanced scenarios, accuracy may not be a good choice because of the bias toward the majority class.”).
See Sordo & Zeng, supra note 65 (comparing multiple classification models while varying the sample size on which they are trained).
Id.
Id.
See Antitrust Modernization Comm’n, supra note 4, at 351 (“[P]roponents of the McCarran-Ferguson Act’s antitrust exemption . . . argue that the sharing of such historical and trending data is needed especially by smaller insurers that otherwise would be unable reasonably to assess risk and compete effectively.”).
See Natthaphan Boonyanunta & Panlop Zeephongsekul, Predicting the Relationship Between the Size of Training Sample and the Predictive Power of Classifiers, in Knowledge-Based Intelligent Information and Engineering Systems 529, 532 (Mircea Gh. Negoita et al. eds., 2004).
Avraham, supra note 53, at 104–05.
For an example of the competitiveness within the insurance industry and the distribution of market share, see Top 40 List of Insurers, Tex. Dep’t Ins., https://www.tdi.texas.gov/company/top40.html [https://perma.cc/6VGM-WDLJ] (Mar. 3, 2021). Within passenger auto insurance in Texas in 2019, the largest insurer has a market share of more than 13%, while the fortieth largest has a market share of less than half a percent. Id.
Proponents of the antitrust exemption also raise the rationale that the exemption allows the insurance industry to establish and share standardized policy forms; however, this rationale is weak given that the practice does not just involve the provision of standardized policy forms but the requirement by rating bureaus that those forms be used. See Macey & Miller, supra note 5, at 53. Additionally, the Antitrust Modernization Commission did not even reference this rationale in its report when it discussed the McCarran-Ferguson Act’s antitrust exemption. See Antitrust Modernization Comm’n, supra note 4, at 351.
See supra Sections II.B–C.
See Herbert Hovenkamp, The Rule of Reason, 70 Fla. L. Rev. 81, 98 (2018).
See Antitrust Modernization Comm’n, supra note 4, at 351 (characterizing the exemption, in the eyes of its proponents, as allowing smaller insurers to “compete effectively”).
Many states already have some form of an antitrust statute that—absent a state exemption—have applied to the insurance industry. See Philip F. Zeidman, Legal Aspects of Selling and Buying § 10:5 (3d ed. 2018). The efficacy of state antitrust regulation and enforcement is not the subject of this Note; however, the ability of states to effectively combat anticompetitive practices has been doubted. See Powrie, supra note 4, at 373 (“In many states, the insurance commission does not have the capacity to regulate or prosecute any anticompetitive behavior by insurance companies.”).
15 U.S.C. § 1; see also Jerry, supra note 29, at 403–04 (arguing that this provision is the most relevant with respect to “concerted insurer conduct”).
Texaco Inc. v. Dagher, 547 U.S. 1, 5 (2006) (quoting Nat’l Soc’y of Prof. Eng’rs v. United States, 435 U.S. 679, 692 (1978)).
Id.
Leegin Creative Leather Prods., Inc. v. PSKS, Inc., 551 U.S. 877, 885–87 (2007) (quoting Cont’l T.V., Inc. v. GTE Sylvania Inc., 433 U.S. 36, 49 (1977)).
See, e.g., Antitrust Modernization Comm’n, supra note 4, at 351; Mark F. Horning, Repeal, Safe Harbors, or Status Quo?: Antitrust Immunity for the Insurance Industry, 8 Antitrust, Spring 1994 , at 14, 15–17 (arguing that “[t]he rule of reason would . . . permit rating organizations to compile aggregated historic loss data” but leaving the question undecided whether the rule of reason would also allow trending and loss development, which both involve data analysis on shared insurer data); Varney, supra note 4, at 782 (“[T]he vast majority of cooperative activities [engaged in by the insurance industry] . . . are now clearly permissible.”).
William Holmes & Melissa Mangiaracina, Antitrust Law Handbook §§ 2:3, 2:7 Westlaw (database updated Dec. 2020).
See id. § 2:7.
See supra Section III.A.
Michael A. Carrier, The Four-Step Rule of Reason, Antitrust, Spring 2019, at 50, 50–51.
See Paolo Coccorese, Information Sharing, Market Competition and Antitrust Intervention: A Lesson from the Italian Insurance Sector, 44 Applied Econ. 351, 352 (2012) (discussing the possibility of information sharing leading to collusion).
Most property and casualty insurance markets are paradigmatic of this category. See Schwarcz, supra note 55, at 973–74; Top 40 List of Insurers, supra note 90.
See Joskow & McLaughlin, supra note 4, at 382–83 (arguing that some insurers may not have sufficient data “to determine [their] expected loss costs with adequate precision”).
See supra Section III.B; Sordo & Zeng, supra note 84, at 194–96.
See Sordo & Zeng, supra note 84, at 195–97.
See Seliya et al., supra note 80, at 59; supra note 83 and accompanying text.
See Haixiang et al., supra note 83, at 227–28.
See supra Section III.A.
The Department of Justice can enforce § 1 of the Sherman Act by bringing a civil action. See 15 U.S.C. § 4. Additionally, private parties may sue for damages sustained from a violation of § 1 and enjoin violations of § 1. See id. §§ 15(a), 26.
Performance, as previously mentioned, being measured by whatever measure is appropriate or desired. It is possible and expected that the parties will differ in what they believe the ideal measure of performance to be for a given model. Considering classification models alone, there is no single or ‘correct’ measure of performance. See Haixiang et al., supra note 83, at 227–28.
For a discussion of learning curves, see supra Section III.B and Figueroa et al., supra note 9, at 2.
The amount of information was sufficient because the performance of both the Random Forests and logistic regression models plateaued before utilizing the entirety of the training set. See supra Section III.B; Boonyanunta & Zeephongsekul, supra note 88 (discussing the concept of “efficiency threshold”).
See supra Sections III.B–C.
See, e.g., Boonyanunta & Zeephongsekul, supra note 88, at 533 (finding that “the relationship between training sample size and predictive power indeed follows a precise mathematical law,” which can be accurately forecasted); Figueroa et al., supra note 9, at 5–6 (similarly finding that learning curves follow a mathematical law that can be forecasted).
See supra note 118 and accompanying text.
See Sordo & Zeng, supra note 84, at 198.
An example of an insurance-related task would be risk classification of insureds. See generally Shi et al., supra note 76, at 423.
See Coccorese, supra note 105.
See id.
As mentioned in this Part, antitrust may be unlikely given that a plaintiff would need to establish “concerted action” and “anticompetitive effect” at the outset. See supra notes 101, 104.